Introduction
Anybody can write a few lines of code for TensorFlow or PyTorch that defines a neural network for Natural Language Understanding tasks. Scientific papers reflecting modern research seem clear enough for implementing in code (eg. Python or Java/DL4J), at least the few ones I reviewed this year and a few before (eg. those on GPT-3, BERT)
However, unless you have a breakthrough neural network architecture to rollout to production, whose pitching won you some capital, i.e. at least a few dozens thousands USD to spare for weeks of TPUs/GPU cluster in AWS/GCP/Azure, you won't be able train a modern competitive language model for Natural Language Understanding tasks anew.
The biggest challenges:
- finding a large enough corpus of coherent text, reviewed by skilled Data Engineers to sort out biased and incorrect parts (hopefully). For example, text corpus of a mid-2021 star of the NLU scene, GPT-3 was close to a terrabyte in size. Its fully open source rival in the 6 Billions parameter counts range, GPT-J-6B was trained on the 800GB "The Pile" source from Reddit
- excessive compute power needed for weeks. For example, training the GPT-3 175B consumed several thousand petaflop/s-days of compute during pre-training,
The NLU tasks in scope are question answering, text summarization, text generation and translation.
As you can judge from text completions by GPT-J , it is not so versed in peculiarities of Cloud Architectures, for example.
That's when Transfter Learning comes in handy. It allows you to re-use the base language model, whose pre-training itself costed a few dozens thousands in compute costs only. Transfer Learning enables feeding pre-trained model with word associations captured in the augmenting text dataset.
Running GPT-J on commodity hardware poses a few challenges by itself:
- unexpected segmentation faults as on screenshots below
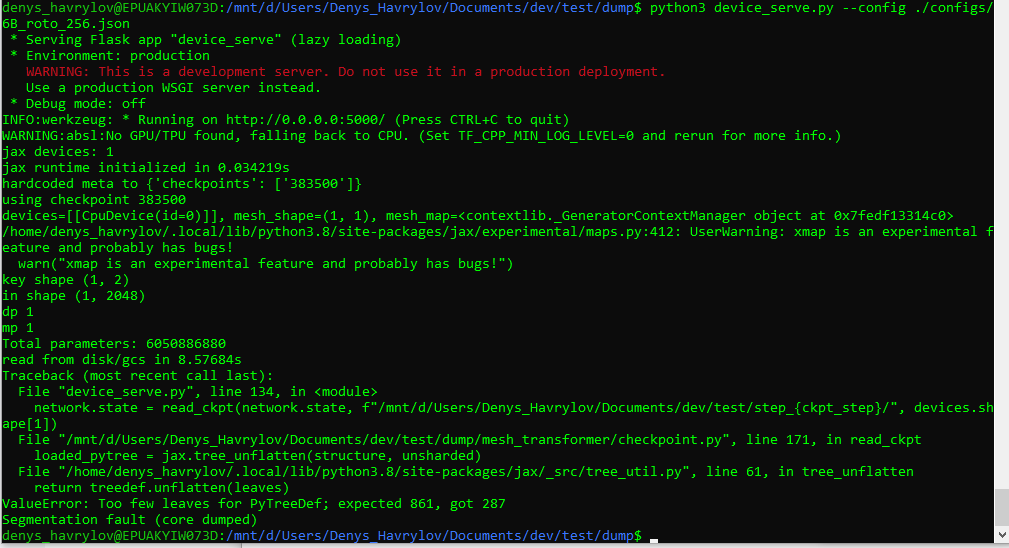
- need to compile JAX/Tensorflow/Torch for your CPU (in case of older CPU models without AVX support) or GPU
- Exact library versions to build depend on GPT-J implementation in use
- JAX-based mesh-transformer-jax would need a JAX build
- HuggingFace's would require PyTorch that runs on your box
- Exact library versions to build depend on GPT-J implementation in use
You might get access to Google's TPU Research Cloud , which would dramatically speed up transfer learning exercises with GPT-J. My application for TRC did not yield yet, though.
References
- https://en.wikipedia.org/wiki/GPT-3
- https://towardsdatascience.com/what-is-gpt-3-and-why-is-it-so-powerful-21ea1ba59811
- https://arxiv.org/pdf/2005.14165.pdf
- https://compstat-lmu.github.io/seminar_nlp_ss20/transfer-learning-for-nlp-ii.html
Note In Web, Inc. © September 2022-2026; Denys Havrylov Ⓒ 2018-August 2022