Metering Business Events in a Multi-Tenant Hadoop Data Lake with Apache Kafka and Spark
Introduction
Servicing a larger number of Data Scientists and development teams productionalizing their ML models and Big Data concepts, would definitely raise concerns of efficiency, reuse and security as scale increases. Then component-level multi-tenancy can offer benefits and superior solutions over whole-stack-deploy-per-each-tenant one (as offered by cloud providers).
In the series of articles "Note Web - Multi-tenant Big Data Lake" we'll present interlinked notes on building such an agile service environment for development teams and individual researches. "Note Web" part in the series' title is not only to reflect the nature of this series - architect's notes, but also is an Active Content Management & Development Platform offered as SaaS at NoteInWeb.com. It is currently in beta-testing.
Arguably, multi-tenancy, metering-monitoring, as well as authentication, authorization, audit are cornerstones of any SaaS/PaaS offering. That's why we'll start with the first two in this series, covering implementation of the others in subsequent articles. There is another such architectural cornerstone present implicitly in any SaaS/PaaS, that NoteWeb would make explicit and put at end users and tenant's control. That's a topic of a different series of articles in development, though.
Multi-tenancy
Multi-tenancy traditionally poses architectural challenges for distributed systems with heterogeneous storage. This cross-cutting concern needs to be implemented holistically across all participating system components and services to deliver coherent and manageable customer experience.
Considering a compute - storage relationship (and thus architectural view) in each given service or component, there are following types of multi-tenancy that can be defined:
- single storage unit of given type for all tenants - i.e. single RDBMS Oracle/MySQL database for all tenants, single HBase table for all tenants. Tenant identifier is embedded in each data record. Single compute component or service instance handles all tenants. This architecture is highly scalable and low cost due to shared resources. Operational Complexity is high though, due to complexer application design and setup.
- single storage unit of given type per each tenant - single compute component or service instance uses tenant id to connect to different tenant specific storage units when processing requests and running asynchronous tasks. This type of multi-tenancy would cover a single Java Spring MVC application connecting to tenant's PostgreSQL for each tenant's request or a Django web application connecting to WebDAV content repository for each tenant. The scalability is lower and cost higher than with single storage unit for all tenants. Operational complexity is lower, primarily complexity of data structures is lower due to tenant dimension out of data structure and higher level data segregation.
- single-tenant compute component or service with single-tenant storage. This approach would cover a JBoss Wildfly server running on a dedicated AWS EC2 instance connecting to a tenant-specific Oracle database and LDAP server. Adding a new tenant would require deploying the whole stack. Thus this type provides higher level of data isolation. The costs for compute and storage are highest, but any single tenant application can service large amount of tenants with this approach.
Though the number of Big Data open source products offering multi-tenancy support out of the box increases (Apache Atlas, Knox, to name a few), resource usage metering and policy enforcing remain among the most interesting concerns for productionizing Big Data applications without much investment into boilerplate like authorization, audit, authentication, data governance, monitoring.
Metering-Monitoring
Cloud providers meter compute and storage resources for billing of each cloud account as part of their business model. This offers multi-tenancy of type 3 and metering. So if spinning up a separate AWS EMR cluster and tasking a DevOps colleague with big data stack setup for every little Data Science research endeavor are fine for your budget, then this article can represent a merely architectural exercise and reading in your case (not necessarily a technical guide for the needs in hand at the this instant).
In this article we'd review usage metering support offered by modern big data containers and processors, preferably with multi-tenancy support of types 1 or 2. Practical part of the article would cover putting up a simple Technical POC for defining Note Web business metrics, setting up metrics collection and rendering status onto an application's and Grafana dashboards. This would also include lower level metrics for the following components:
- Apache Spark (v2.3.4)
- Apache Kafka
- Apache Hadoop HDFS Storage
- Jackrabbit JCR Storage
- Apache HBase
- ElasticSearch
- MySQL
Requirements
At high level metering solution requirements can be grouped into:
- Resource usage policy definition - what kinds of events (CRUD and business) you would like your system to emit, which event streams are normal, which indicate a problem state, which conditions are not allowed
- Policy enforcing - how should system react at policy violations, intended and occurred
- Policy monitoring - what statistics are to be gathered over resource usage, event streams emitted, how statistics are to be aggregated and displayed
[Policy Monitoring] NW Tenant and User Metrics Boards
NW Tenant board should display resource and content usage statistics at the tenant account level. User Board would represent the same for the individual user account. CRUD and business event streams are to be produced by each Note Web micro service and component, routed via Apache Kafka, processed by Apache Spark streaming, event stream statistics are to be aggregated at Note Web tag level, charted on Note Web and Grafana boards. Both push and pull approaches for metrics collections to be supported.
[Policy Definition] Data Structure
In Note Web every business entity starts with a note. Note's purpose and behavior, including data structure and available actions evolve further as it is assigned Tags.
Tags:
- Resource Metrics
- Storage
- By Container
- Compute
- By Processor Type
- Storage
- Business Metrics
- Tags
- Notes
- Tag Types
- Contexts
- Boards
Architecture
Authentication and Authorization services are provided by KeyCloak for non-Hadoop components and Apache Ranger for the Hadoop stack parts. Hadoop data governance is covered by Apache Atlas. Tenant and user accounts are stored in Note Web's LDAP server. Apache Kafka facilitates event streams. Apache Spark Streaming aggregates event streams at necessary levels and pushes data for the monitoring dashboards. Kubernetes Namespaces provide tenant segregation for tenant-specific services.
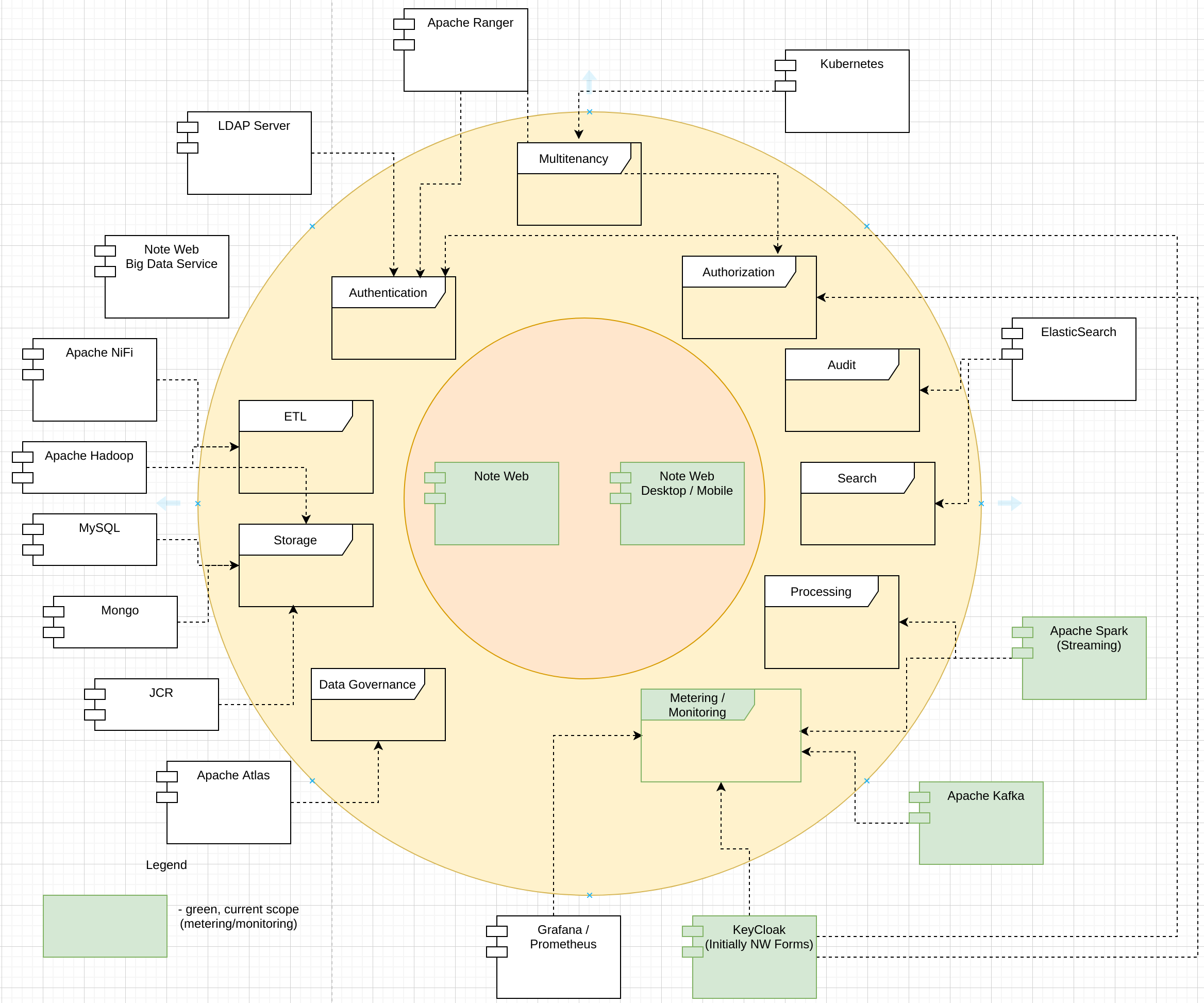
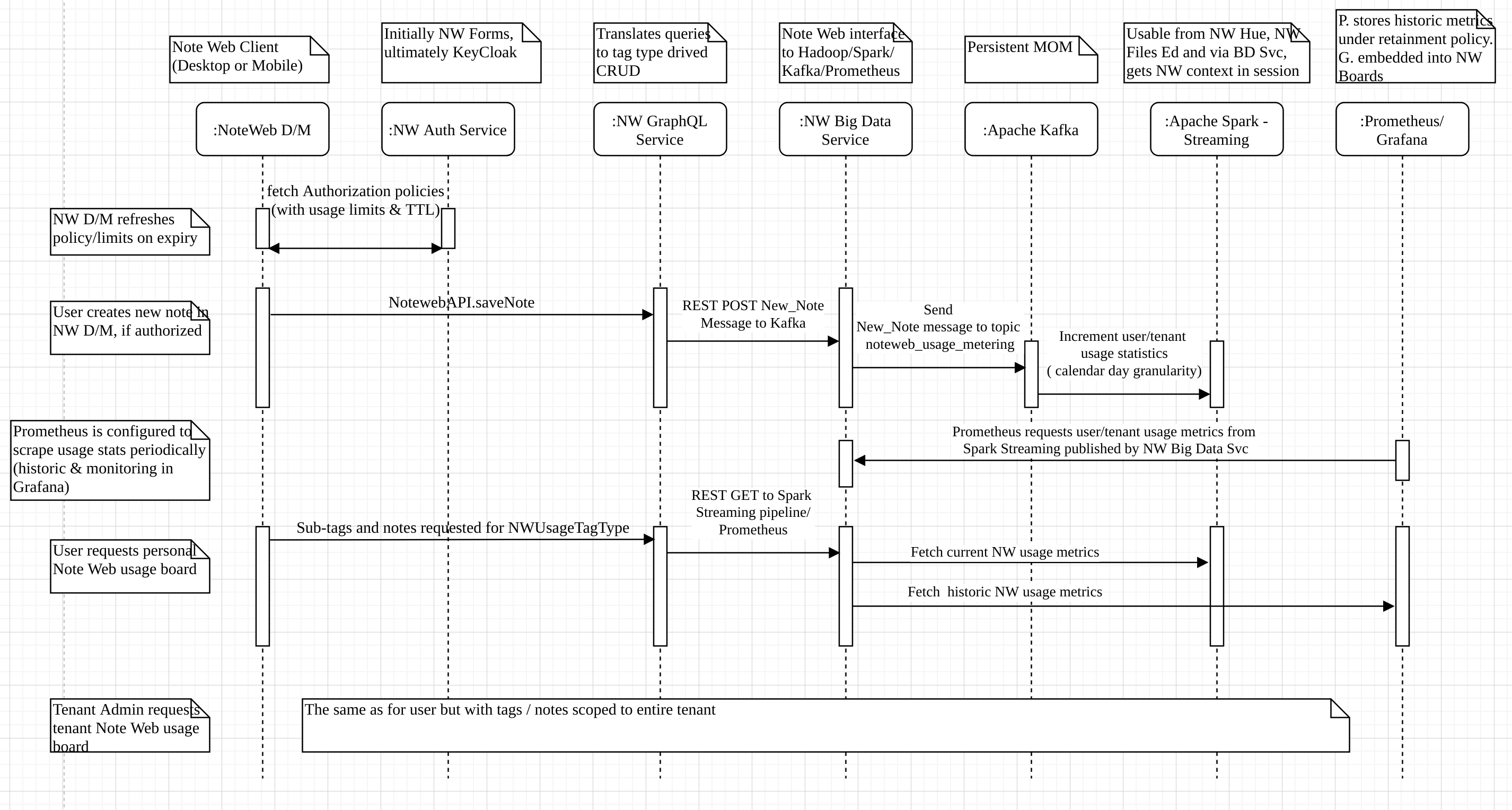
Main Data Flow cases are displayed on the UML sequence diagram below:
References
- https://medium.com/crunchyroll/multi-tenancy-for-big-data-part-2-c8b66a3fae89
Note In Web, Inc. © September 2022-2026; Denys Havrylov Ⓒ 2018-August 2022