Decision Trees in Note Web
Background
There are plenty of articles and books covering the topic of decision trees to solve classification problem in Machine Learning (see References below for the few used in this post). These books and articles cover statistical foundations and the many machine learning libraries that'd do all the calculations for us, if we choose to use decision trees in our case.
There is one leap of thought often remaining implicit in many sources, though. Most likely obvious for majority of readers novadays, but this bit has impressed me back in 1998 as I studied Statistics for my Master's in Computer Science, majoring "Intellectual Decision Making Systems in Macroeconomics" in Kiev, Ukraine.
Almost at the same time we studied technologies like Prolog and Business Rules Engines (for Expert Systems) and how their production subsystems work under the hood. The leitmotiv for these course topics was - Its human expert's knowledge and experience that build most efficient decison trees.
Still, here is a simple algorithm that can turn the whole dataset into a rules base automatically. (While such particular outcome for plain decision trees is not desired and is called overfitting, is a frequent foe of a data scientist.) However, the bottomline stands: back then and even few dozens years before that, machines wrote programs for machines based on environment data automatically.
MDA in 90s, metadata-driven code generators, 0-code and systems like Trinity of Apple and Codex/GitHub Copilot of OpenAI today - do we really advance in directioin of self-propelled computer evolution or only trick each other into thinking we do? Did the Math underlying these systems change that much over these few decades? No matter what the answer to these questions are, as a Scientist you are expected to understand the algorithms you apply, interpret the metrics for top suggested models, their internal structure and state, tune parameters and develop solutions further.
Decision trees are good to illustrate such "nuts and bolts" approach, since you can easily output the internal structure of the model in a user-friendly manner. That's what I'd like to show in this article.
Fit a decision tree in Scikit-Learn and dump model representation
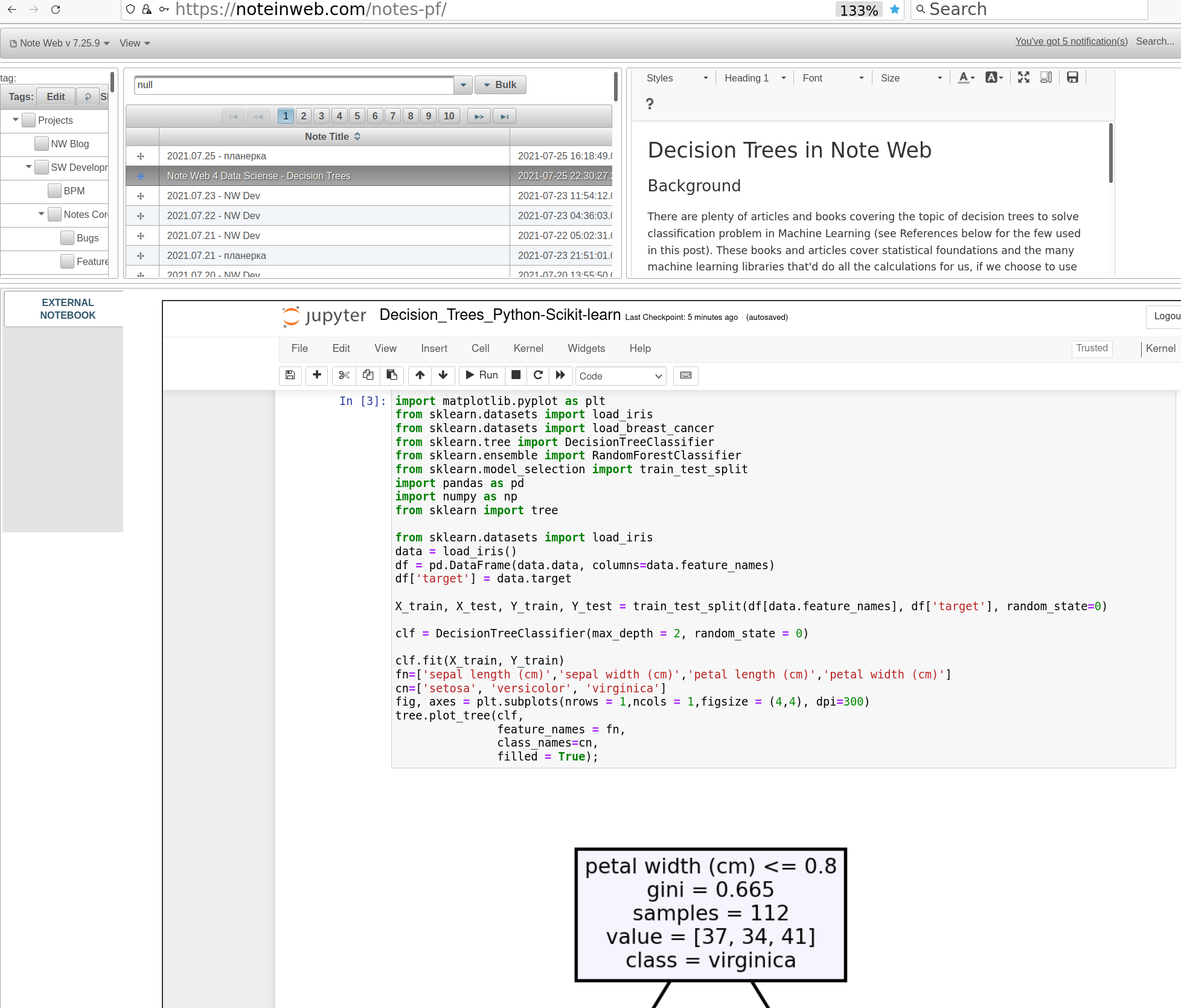
Code below would load a well known iris dataset from SciKit-Learn, split the data set into training and tests subsets, fit the tree and render built model as a graph (skipping model verification by predicting test data):
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.datasets import load_iris
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
X_train, X_test, Y_train, Y_test = train_test_split(df[data.feature_names], df['target'], random_state=0)
clf = DecisionTreeClassifier(max_depth = 2, random_state = 0)
clf.fit(X_train, Y_train)
fn=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']
cn=['setosa', 'versicolor', 'virginica']
fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=300)
tree.plot_tree(clf,
feature_names = fn,
class_names=cn,
filled = True);
You can see the output in your Jupyter notebook or in your note on NoteInWeb.com:
Combat Overfitting with Random Forests, Visualize Selected Estimators
As mentioned above, you can improve generalizability of a decision tree (and single estimator for this matter) using so called ensemble methods. Generalizability (or method robustness) is what you optimize when fixing overfitting. Ensemble methods can be broadly categorized into :
- averaging methods - build several estimators independently and then average their predictions. Combined estimator is usually better than any single base estimator due to reduced variance.
- boosting methods - base estimators are built sequentially , reducing the bias of a combined estimator. Approach is to combine several weak models to generate a stronger ensemble.
data = load_wine()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target# Arrange Data into Features Matrix and Target Vector
X = df.loc[:, df.columns != 'target']
y = df.loc[:, 'target'].values# Split the data into training and testing sets
X_train, X_test, Y_train, Y_test = train_test_split(X, y, random_state=0)# Random Forests in `scikit-learn` (with N = 100)
rf = RandomForestClassifier(n_estimators=100,
random_state=0)
rf.fit(X_train, Y_train)
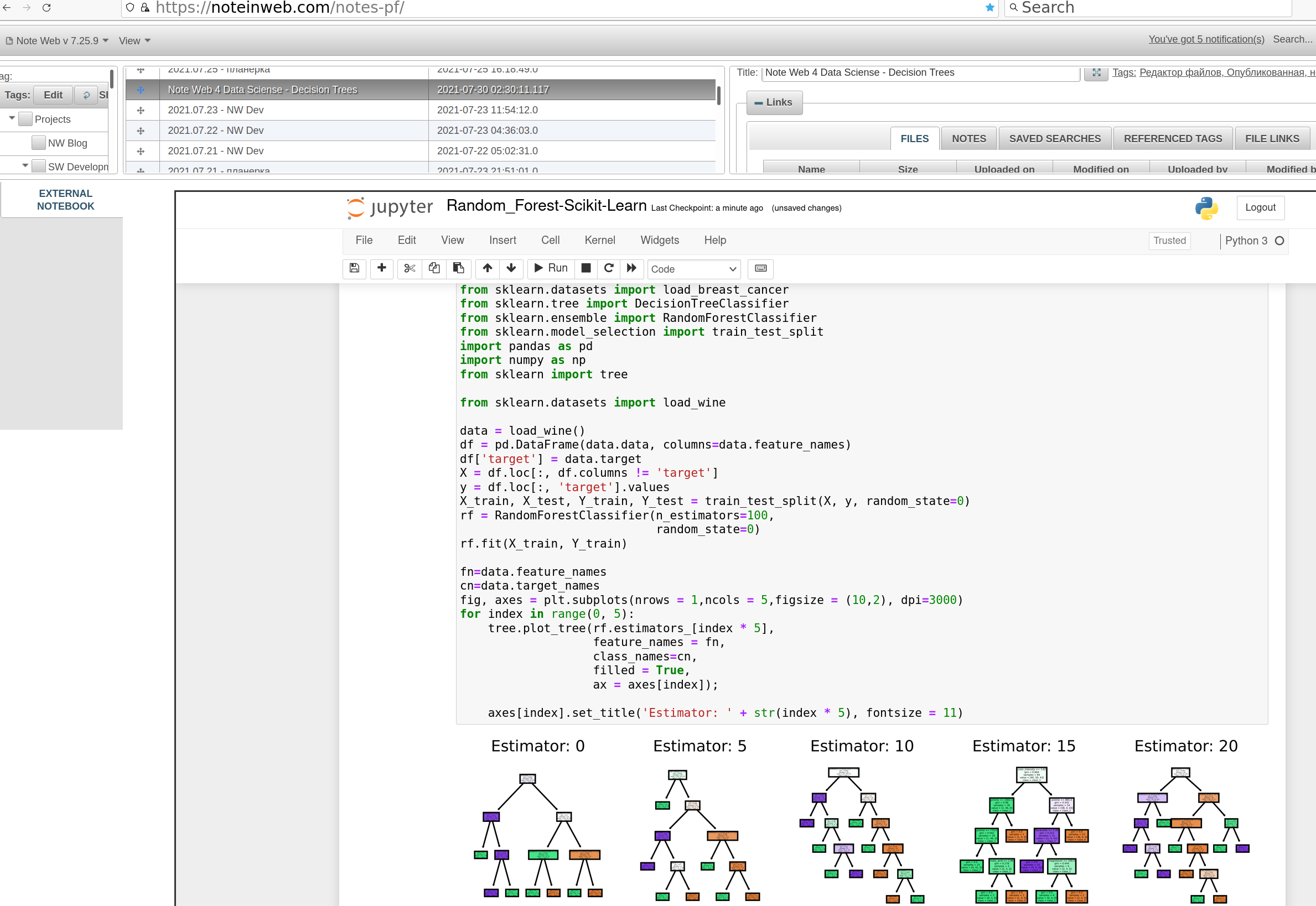
You can use automated selection criteria to select most interesting trees to visualize , but code snippet below just dumps each 5th:
fn=data.feature_names
cn=data.target_names
fig, axes = plt.subplots(nrows = 1,ncols = 5,figsize = (10,2), dpi=3000)for index in range(0, 5):
tree.plot_tree(rf.estimators_[index],
feature_names = fn,
class_names=cn,
filled = True,
ax = axes[index]);
axes[index].set_title('Estimator: ' + str(index), fontsize = 11)
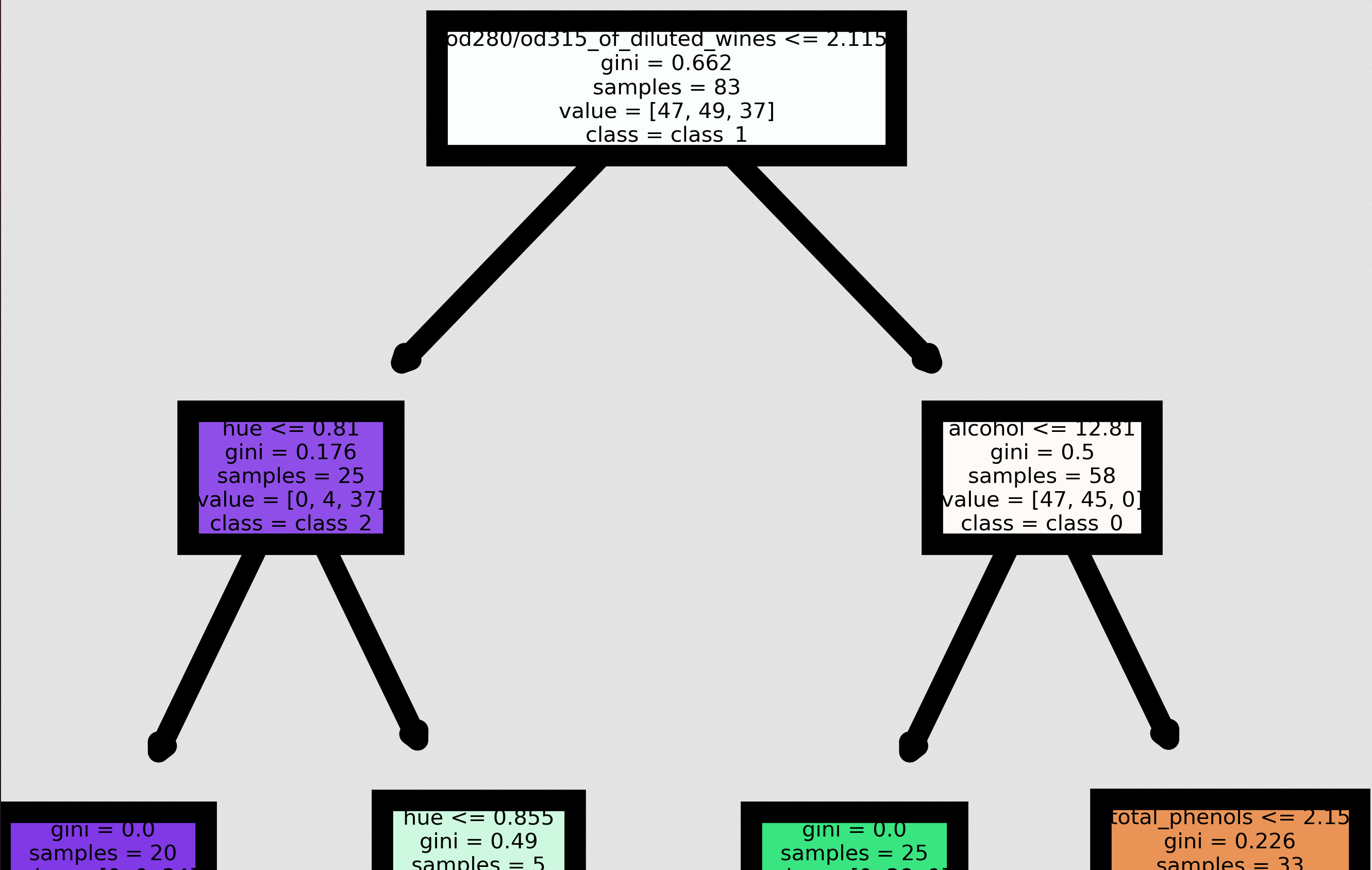
The output might seem unreadable, but you can see each trees detail if you click on the image:
Explain Spark Scala Decision Tree Model Parameters
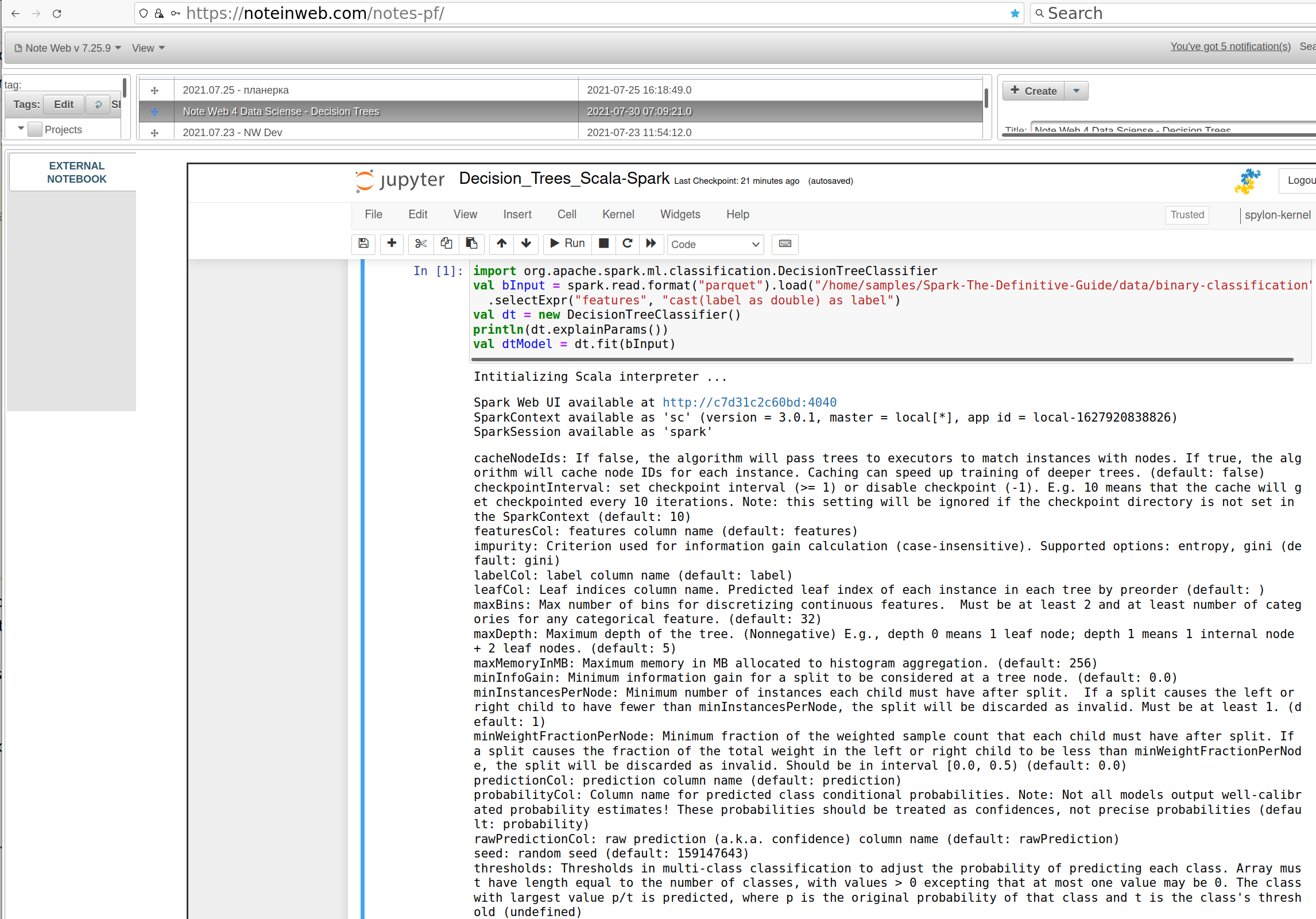
It is just as simple to train a Decision Tree model for a Spark Data Frame:
val bInput = spark.read.format("parquet").load("/home/samples/Spark-The-Definitive-Guide/data/binary-classification")
.selectExpr("features", "cast(label as double) as label")
val dt = new DecisionTreeClassifier()
println(dt.explainParams())
val dtModel = dt.fit(bInput)
Spark Scala and Python libs can provide detailed explanation for model parameters:
Conclusion
Even though Data Science libs require only a few lines of code to fit and investigate model, be it Python (SciKit-Learn or PySpark), Scala or R, we still need to understand the properties, structure and state of the best models.
This task gets yet more challenging once you decide to automate training and investigation of larger number of models built by different algorithms. We'll cover this topic a bit in the next article "Evaluators and Automating Model Tuning, Model Metrics". Upcoming article on use of H2O with Note Web would provide a yet better example of how it can be achieved at scale.
References
- ISBN 978-1491912058 Jake VanderPlas "Python Data Science Handbook: Essential Tools for Working with Data 1st Edition "
- https://scikit-learn.org/stable/modules/ensemble.html
- https://towardsdatascience.com/visualizing-decision-trees-with-python-scikit-learn-graphviz-matplotlib-1c50b4aa68dc
- https://spark.apache.org/docs/latest/ml-classification-regression.html#tree-ensembles
- https://play.google.com/books/reader?id=pitLDwAAQBAJ&pg=GBS.PT541.w.3.0.9
- ISL 8.2 and ESL 10.1
- https://machinelearning.apple.com/research/complex-spatial-datasets
Note In Web, Inc. © September 2022-2026; Denys Havrylov © 2018-August 2022